Deploying yolort on TensorRT¶
Unlike other pipelines that deal with yolov5 on TensorRT, we embed the whole post-processing into the Graph with onnx-graghsurgeon. We gain a lot with this whole pipeline. The ablation experiment results are below. The first one is the result without running EfficientNMS_TRT, and the second one is the result with EfficientNMS_TRT embedded. As you can see, the inference time is even reduced, we guess it is because the data copied to the device will be much less after doing
EfficientNMS_TRT. (The mean Latency of D2H is reduced from 0.868048 ms to 0.0102295 ms, running on Nivdia Geforce GTX 1080ti, using TensorRT 8.2 with yolov5n6 and scaling images to 512x640.)
And onnx-graphsurgeon is easy to install, you can just use their prebuilt wheels:
python3 -m pip install onnx_graphsurgeon --index-url https://pypi.ngc.nvidia.com
The detailed results:
[I] === Performance summary w/o EfficientNMS_TRT plugin ===
[I] Throughput: 383.298 qps
[I] Latency: min = 3.66479 ms, max = 5.41199 ms, mean = 4.00543 ms, median = 3.99316 ms, percentile(99%) = 4.23831 ms
[I] End-to-End Host Latency: min = 3.76599 ms, max = 6.45874 ms, mean = 5.08597 ms, median = 5.07544 ms, percentile(99%) = 5.50839 ms
[I] Enqueue Time: min = 0.743408 ms, max = 5.27966 ms, mean = 0.940805 ms, median = 0.924805 ms, percentile(99%) = 1.37329 ms
[I] H2D Latency: min = 0.502045 ms, max = 0.62674 ms, mean = 0.538255 ms, median = 0.537354 ms, percentile(99%) = 0.582153 ms
[I] GPU Compute Time: min = 2.23233 ms, max = 3.92395 ms, mean = 2.59913 ms, median = 2.58661 ms, percentile(99%) = 2.8201 ms
[I] D2H Latency: min = 0.851807 ms, max = 0.900421 ms, mean = 0.868048 ms, median = 0.867676 ms, percentile(99%) = 0.889191 ms
[I] Total Host Walltime: 3.0081 s
[I] Total GPU Compute Time: 2.99679 s
[I] Explanations of the performance metrics are printed in the verbose logs.
[I]
&&&& PASSED TensorRT.trtexec [TensorRT v8201] # trtexec --onnx=yolov5n6-no-nms.onnx --workspace=8096
[I] === Performance summary w/ EfficientNMS_TRT plugin ===
[I] Throughput: 389.234 qps
[I] Latency: min = 2.81482 ms, max = 9.77234 ms, mean = 3.1062 ms, median = 3.07642 ms, percentile(99%) = 3.33548 ms
[I] End-to-End Host Latency: min = 2.82202 ms, max = 11.6749 ms, mean = 4.939 ms, median = 4.95587 ms, percentile(99%) = 5.45207 ms
[I] Enqueue Time: min = 0.999878 ms, max = 11.3833 ms, mean = 1.28942 ms, median = 1.18579 ms, percentile(99%) = 4.53088 ms
[I] H2D Latency: min = 0.488159 ms, max = 0.633881 ms, mean = 0.546754 ms, median = 0.546631 ms, percentile(99%) = 0.570557 ms
[I] GPU Compute Time: min = 2.30298 ms, max = 9.21094 ms, mean = 2.54921 ms, median = 2.51904 ms, percentile(99%) = 2.78528 ms
[I] D2H Latency: min = 0.00610352 ms, max = 0.302734 ms, mean = 0.0102295 ms, median = 0.00976562 ms, percentile(99%) = 0.0151367 ms
[I] Total Host Walltime: 3.00591 s
[I] Total GPU Compute Time: 2.98258 s
[I] Explanations of the performance metrics are printed in the verbose logs.
[I]
&&&& PASSED TensorRT.trtexec [TensorRT v8201] # trtexec --onnx=yolov5n6-efficient-nms.onnx --workspace=8096
TensorRT Installation Instructions¶
For us to unfold the subsequent story, TensorRT should be installed and the minimal version of TensorRT to run this demo is 8.2.0. Check out the TensorRT installation guides at https://docs.nvidia.com/deeplearning/tensorrt/install-guide/index.html. You can use the Python wheels provided by TensorRT if you only want to use the Python interface:
pip install -U nvidia-tensorrt --index-url https://pypi.ngc.nvidia.com
These wheels only works on Ubuntu 18.04+ or CentOS 7+ with Python versions 3.6 to 3.9 and CUDA 11.x. Check out the details at https://docs.nvidia.com/deeplearning/tensorrt/install-guide/index.html#installing-pip.
There are many ways to install the whole TensorRT at https://docs.nvidia.com/deeplearning/tensorrt/install-guide/index.html#installing. One option to use the C++ interface of TensorRT is via docker. We’ve tested the docker published by Meta (Facebook) containing the TensorRT and PyTorch at NVIDIA GPU Cloud (NGC): https://catalog.ngc.nvidia.com/orgs/nvidia/containers/pytorch.
[1]:
import os
import torch
os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID"
cuda_visible = "0"
os.environ["CUDA_VISIBLE_DEVICES"] = cuda_visible
assert torch.cuda.is_available()
device = torch.device('cuda')
import tensorrt as trt
print(f"We're using TensorRT: {trt.__version__} on {device} device: {cuda_visible}.")
We're using TensorRT: 8.2.4.2 on cuda device: 0.
[2]:
import cv2
from yolort.utils import Visualizer
from yolort.v5 import attempt_download
from yolort.v5.utils.downloads import safe_download
Prepare image and model weights to test¶
[3]:
# Define some parameters
batch_size = 1
img_size = 640
size_divisible = 32
fixed_shape = True
score_thresh = 0.35
nms_thresh = 0.45
detections_per_img = 100
# Must upgrade TensorRT to 8.2.4 or higher to use fp16 mode.
precision = "fp16"
[4]:
# img_source = "https://huggingface.co/spaces/zhiqwang/assets/resolve/main/zidane.jpg"
img_source = "https://huggingface.co/spaces/zhiqwang/assets/resolve/main/bus.jpg"
img_path = img_source.split("/")[-1]
safe_download(img_path, img_source)
img_raw = cv2.imread(img_path)
Downloading https://huggingface.co/spaces/zhiqwang/assets/resolve/main/bus.jpg to bus.jpg...
[5]:
# yolov5s6.pt is downloaded from 'https://github.com/ultralytics/yolov5/releases/download/v6.0/yolov5n6.pt'
model_path = "yolov5s.pt"
checkpoint_path = attempt_download(model_path)
onnx_path = "yolov5s.onnx"
engine_path = "yolov5s.engine"
Export to ONNX and TensorRT model¶
We provide a utilization tool export_tensorrt_engine for exporting TensorRT engines.
[6]:
from yolort.runtime.trt_helper import export_tensorrt_engine
[7]:
input_sample = torch.rand(batch_size, 3, img_size, img_size)
[8]:
export_tensorrt_engine(
model_path,
score_thresh=score_thresh,
nms_thresh=nms_thresh,
onnx_path=onnx_path,
engine_path=engine_path,
input_sample=input_sample,
detections_per_img=detections_per_img,
precision=precision
)
Loaded saved model from yolov5s.pt
/root/miniconda3/envs/torch/lib/python3.8/site-packages/torch/functional.py:568: UserWarning: torch.meshgrid: in an upcoming release, it will be required to pass the indexing argument. (Triggered internally at ../aten/src/ATen/native/TensorShape.cpp:2228.)
return _VF.meshgrid(tensors, **kwargs) # type: ignore[attr-defined]
/workspace/yolo/yolort/yolort/models/anchor_utils.py:46: TracerWarning: torch.as_tensor results are registered as constants in the trace. You can safely ignore this warning if you use this function to create tensors out of constant variables that would be the same every time you call this function. In any other case, this might cause the trace to be incorrect.
anchors = torch.as_tensor(self.anchor_grids, dtype=torch.float32, device=device).to(dtype=dtype)
/workspace/yolo/yolort/yolort/models/anchor_utils.py:47: TracerWarning: torch.as_tensor results are registered as constants in the trace. You can safely ignore this warning if you use this function to create tensors out of constant variables that would be the same every time you call this function. In any other case, this might cause the trace to be incorrect.
strides = torch.as_tensor(self.strides, dtype=torch.float32, device=device).to(dtype=dtype)
/workspace/yolo/yolort/yolort/relay/logits_decoder.py:45: TracerWarning: torch.as_tensor results are registered as constants in the trace. You can safely ignore this warning if you use this function to create tensors out of constant variables that would be the same every time you call this function. In any other case, this might cause the trace to be incorrect.
strides = torch.as_tensor(self.strides, dtype=torch.float32, device=device).to(dtype=dtype)
/workspace/yolo/yolort/yolort/models/box_head.py:337: TracerWarning: Iterating over a tensor might cause the trace to be incorrect. Passing a tensor of different shape won't change the number of iterations executed (and might lead to errors or silently give incorrect results).
for head_output, grid, shift, stride in zip(head_outputs, grids, shifts, strides):
PyTorch2ONNX graph created successfully
[W] 'Shape tensor cast elision' routine failed with: None
Created NMS plugin 'EfficientNMS_TRT' with attributes: {'plugin_version': '1', 'background_class': -1, 'max_output_boxes': 100, 'score_threshold': 0.35, 'iou_threshold': 0.45, 'score_activation': False, 'box_coding': 0}
Saved ONNX model to yolov5s.onnx
Network Description
Input 'images' with shape (1, 3, 640, 640) and dtype DataType.FLOAT
Output 'num_detections' with shape (1, 1) and dtype DataType.INT32
Output 'detection_boxes' with shape (1, 100, 4) and dtype DataType.FLOAT
Output 'detection_scores' with shape (1, 100) and dtype DataType.FLOAT
Output 'detection_classes' with shape (1, 100) and dtype DataType.INT32
Building fp16 Engine in yolov5s.engine
[05/22/2022-11:13:24] [TRT] [I] [MemUsageChange] Init CUDA: CPU +457, GPU +0, now: CPU 674, GPU 354 (MiB)
[05/22/2022-11:13:24] [TRT] [I] [MemUsageSnapshot] Begin constructing builder kernel library: CPU 674 MiB, GPU 354 MiB
[05/22/2022-11:13:24] [TRT] [I] [MemUsageSnapshot] End constructing builder kernel library: CPU 828 MiB, GPU 398 MiB
[05/22/2022-11:13:24] [TRT] [I] ----------------------------------------------------------------
[05/22/2022-11:13:24] [TRT] [I] Input filename: yolov5s.onnx
[05/22/2022-11:13:24] [TRT] [I] ONNX IR version: 0.0.8
[05/22/2022-11:13:24] [TRT] [I] Opset version: 11
[05/22/2022-11:13:24] [TRT] [I] Producer name:
[05/22/2022-11:13:24] [TRT] [I] Producer version:
[05/22/2022-11:13:24] [TRT] [I] Domain:
[05/22/2022-11:13:24] [TRT] [I] Model version: 0
[05/22/2022-11:13:24] [TRT] [I] Doc string:
[05/22/2022-11:13:24] [TRT] [I] ----------------------------------------------------------------
[05/22/2022-11:13:24] [TRT] [W] parsers/onnx/onnx2trt_utils.cpp:364: Your ONNX model has been generated with INT64 weights, while TensorRT does not natively support INT64. Attempting to cast down to INT32.
[05/22/2022-11:13:24] [TRT] [W] parsers/onnx/onnx2trt_utils.cpp:392: One or more weights outside the range of INT32 was clamped
[05/22/2022-11:13:24] [TRT] [W] parsers/onnx/onnx2trt_utils.cpp:392: One or more weights outside the range of INT32 was clamped
[05/22/2022-11:13:24] [TRT] [W] parsers/onnx/onnx2trt_utils.cpp:392: One or more weights outside the range of INT32 was clamped
[05/22/2022-11:13:24] [TRT] [W] parsers/onnx/onnx2trt_utils.cpp:392: One or more weights outside the range of INT32 was clamped
[05/22/2022-11:13:24] [TRT] [I] No importer registered for op: EfficientNMS_TRT. Attempting to import as plugin.
[05/22/2022-11:13:24] [TRT] [I] Searching for plugin: EfficientNMS_TRT, plugin_version: 1, plugin_namespace:
[05/22/2022-11:13:24] [TRT] [I] Successfully created plugin: EfficientNMS_TRT
[05/22/2022-11:13:25] [TRT] [I] [MemUsageChange] Init cuBLAS/cuBLASLt: CPU +850, GPU +368, now: CPU 1711, GPU 766 (MiB)
[05/22/2022-11:13:25] [TRT] [I] [MemUsageChange] Init cuDNN: CPU +125, GPU +58, now: CPU 1836, GPU 824 (MiB)
[05/22/2022-11:13:25] [TRT] [I] Local timing cache in use. Profiling results in this builder pass will not be stored.
Serialize engine success, saved as yolov5s.engine
[05/22/2022-11:17:18] [TRT] [I] Detected 1 inputs and 4 output network tensors.
[05/22/2022-11:17:18] [TRT] [I] Total Host Persistent Memory: 136048
[05/22/2022-11:17:18] [TRT] [I] Total Device Persistent Memory: 15027712
[05/22/2022-11:17:18] [TRT] [I] Total Scratch Memory: 40320768
[05/22/2022-11:17:18] [TRT] [I] [MemUsageStats] Peak memory usage of TRT CPU/GPU memory allocators: CPU 17 MiB, GPU 4371 MiB
[05/22/2022-11:17:18] [TRT] [I] [BlockAssignment] Algorithm ShiftNTopDown took 4.87204ms to assign 7 blocks to 82 nodes requiring 52404225 bytes.
[05/22/2022-11:17:18] [TRT] [I] Total Activation Memory: 52404225
[05/22/2022-11:17:18] [TRT] [I] [MemUsageChange] Init cuBLAS/cuBLASLt: CPU +0, GPU +8, now: CPU 4880, GPU 2272 (MiB)
[05/22/2022-11:17:18] [TRT] [I] [MemUsageChange] Init cuDNN: CPU +0, GPU +8, now: CPU 4880, GPU 2280 (MiB)
[05/22/2022-11:17:18] [TRT] [I] [MemUsageChange] TensorRT-managed allocation in building engine: CPU +14, GPU +15, now: CPU 14, GPU 15 (MiB)
Test the exported TensorRT engine¶
Actually the above exported TensorRT engine only contains the post-processing (nms). And we wrap the pre-processing named YOLOTransform into a new module PredictorTRT for easy of use.
[9]:
from yolort.runtime import PredictorTRT
[10]:
y_runtime = PredictorTRT(engine_path, device=device)
Loading yolov5s.engine for TensorRT inference...
[05/22/2022-11:18:38] [TRT] [I] [MemUsageChange] Init CUDA: CPU +457, GPU +0, now: CPU 550, GPU 354 (MiB)
[05/22/2022-11:18:38] [TRT] [I] Loaded engine size: 17 MiB
[05/22/2022-11:18:39] [TRT] [I] [MemUsageChange] Init cuBLAS/cuBLASLt: CPU +850, GPU +368, now: CPU 1426, GPU 740 (MiB)
[05/22/2022-11:18:39] [TRT] [I] [MemUsageChange] Init cuDNN: CPU +126, GPU +58, now: CPU 1552, GPU 798 (MiB)
[05/22/2022-11:18:39] [TRT] [I] [MemUsageChange] TensorRT-managed allocation in engine deserialization: CPU +0, GPU +14, now: CPU 0, GPU 14 (MiB)
[05/22/2022-11:18:40] [TRT] [I] [MemUsageChange] Init cuBLAS/cuBLASLt: CPU +0, GPU +10, now: CPU 3366, GPU 1696 (MiB)
[05/22/2022-11:18:40] [TRT] [I] [MemUsageChange] Init cuDNN: CPU +1, GPU +8, now: CPU 3367, GPU 1704 (MiB)
[05/22/2022-11:18:40] [TRT] [I] [MemUsageChange] TensorRT-managed allocation in IExecutionContext creation: CPU +0, GPU +64, now: CPU 0, GPU 78 (MiB)
Let’s warmup the engine by running inference once for GPU device.
[11]:
y_runtime.warmup()
Inferencing with TensorRT¶
[12]:
%%timeit
predictions_trt = y_runtime.predict(img_path)
9.34 ms ± 145 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
[13]:
predictions_trt = y_runtime.predict(img_path)
[14]:
predictions_trt
[14]:
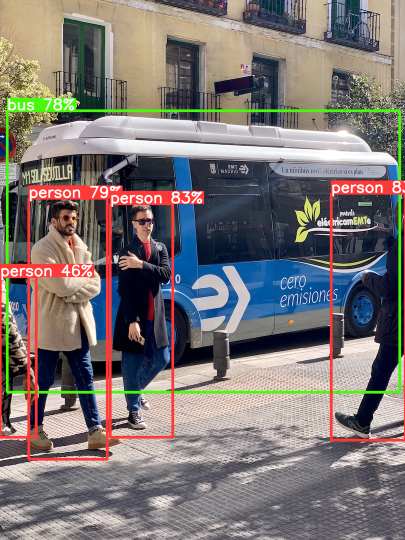
[{'scores': tensor([0.83350, 0.82812, 0.78564, 0.77734, 0.46313], device='cuda:0'),
'labels': tensor([0, 0, 0, 5, 0], device='cuda:0', dtype=torch.int32),
'boxes': tensor([[220.85156, 407.53125, 345.51562, 874.96875],
[662.34375, 386.64844, 810.84375, 880.87500],
[ 57.58594, 396.98438, 214.94531, 918.00000],
[ 14.55469, 221.69531, 799.03125, 784.68750],
[ -0.94922, 553.50000, 72.45703, 874.96875]], device='cuda:0')}]
Predict as yolort¶
[15]:
from yolort.models import YOLOv5
[16]:
model = YOLOv5.load_from_yolov5(
model_path,
size=(img_size, img_size),
size_divisible=size_divisible,
fixed_shape=(img_size, img_size),
score_thresh=score_thresh,
nms_thresh=nms_thresh,
)
model = model.eval()
model = model.to(device)
Inferencing with PyTorch¶
[17]:
predictions_pt = model.predict(img_path)
/root/miniconda3/envs/torch/lib/python3.8/site-packages/torch/functional.py:568: UserWarning: torch.meshgrid: in an upcoming release, it will be required to pass the indexing argument. (Triggered internally at ../aten/src/ATen/native/TensorShape.cpp:2228.)
return _VF.meshgrid(tensors, **kwargs) # type: ignore[attr-defined]
[18]:
predictions_trt
[18]:
[{'scores': tensor([0.83350, 0.82812, 0.78564, 0.77734, 0.46313], device='cuda:0'),
'labels': tensor([0, 0, 0, 5, 0], device='cuda:0', dtype=torch.int32),
'boxes': tensor([[220.85156, 407.53125, 345.51562, 874.96875],
[662.34375, 386.64844, 810.84375, 880.87500],
[ 57.58594, 396.98438, 214.94531, 918.00000],
[ 14.55469, 221.69531, 799.03125, 784.68750],
[ -0.94922, 553.50000, 72.45703, 874.96875]], device='cuda:0')}]
[19]:
predictions_pt
[19]:
[{'scores': tensor([0.83449, 0.82892, 0.78632, 0.78010, 0.46298], device='cuda:0'),
'labels': tensor([0, 0, 0, 5, 0], device='cuda:0'),
'boxes': tensor([[220.82433, 407.41098, 345.70523, 874.90283],
[662.59210, 386.32590, 810.79279, 880.39319],
[ 57.56377, 397.15387, 215.05116, 918.31415],
[ 14.63786, 221.99287, 798.34180, 784.72064],
[ -1.00095, 553.44971, 72.44920, 874.67841]], device='cuda:0')}]
Verify the detection results between yolort and TensorRT¶
[20]:
# Testing boxes
torch.testing.assert_close(predictions_pt[0]["boxes"] / img_size,
predictions_trt[0]["boxes"] / img_size,
atol=1e-3, rtol=1e-3)
# Testing scores
torch.testing.assert_close(predictions_pt[0]["scores"].round(decimals=2),
predictions_trt[0]["scores"].round(decimals=2),
atol=1e-3, rtol=1e-3)
# Testing labels
torch.testing.assert_close(predictions_pt[0]["labels"],
predictions_trt[0]["labels"].to(dtype=torch.int64),
atol=1e-3, rtol=1e-3)
print("Exported model has been tested, and the result looks good!")
Exported model has been tested, and the result looks good!
Visualize the TensorRT detections¶
Get label names first.
[21]:
# label_path = "https://raw.githubusercontent.com/zhiqwang/yolort/main/notebooks/assets/coco.names"
label_source = "https://huggingface.co/spaces/zhiqwang/assets/resolve/main/coco.names"
label_path = label_source.split("/")[-1]
safe_download(label_path, label_source)
Downloading https://huggingface.co/spaces/zhiqwang/assets/resolve/main/coco.names to coco.names...
[22]:
v = Visualizer(img_raw, metalabels=label_path)
v.draw_instance_predictions(predictions_trt[0])
v.imshow(scale=0.5)
View this document as a notebook: https://github.com/zhiqwang/yolort/blob/main/notebooks/onnx-graphsurgeon-inference-tensorrt.ipynb